
Structured Document Processing with Microsoft Syntex
Overview
Structured document processing model works best for structured and semi-structured documents including forms and invoices.
In this article, we will explore Structured document processing model and how to use it in invoices processing scenario.
Structured document processing
Structured document processing model uses Microsoft Power Apps AI Builder to create and train models within Microsoft Syntex. It can be used to process the documents received over mail, fax, and email.
Structured document processing model helps to extract out the key-value pairs and table data from structured and semi-structured documents.
Business Scenario
Let us take a scenario, where we are receiving invoices from multiple vendors (e.g., Adatum and Contoso). Adatum shares the invoices over an email. Whereas invoices received from Contoso are in scanned format. Each of them follows its format to share the invoices.

You may use the Invoices sample data for setting up the model.
Create a Structured document processing model
Follow the below steps to create a structured document processing model:
- Open the content center in SharePoint.
- From the top navigation, click Models.
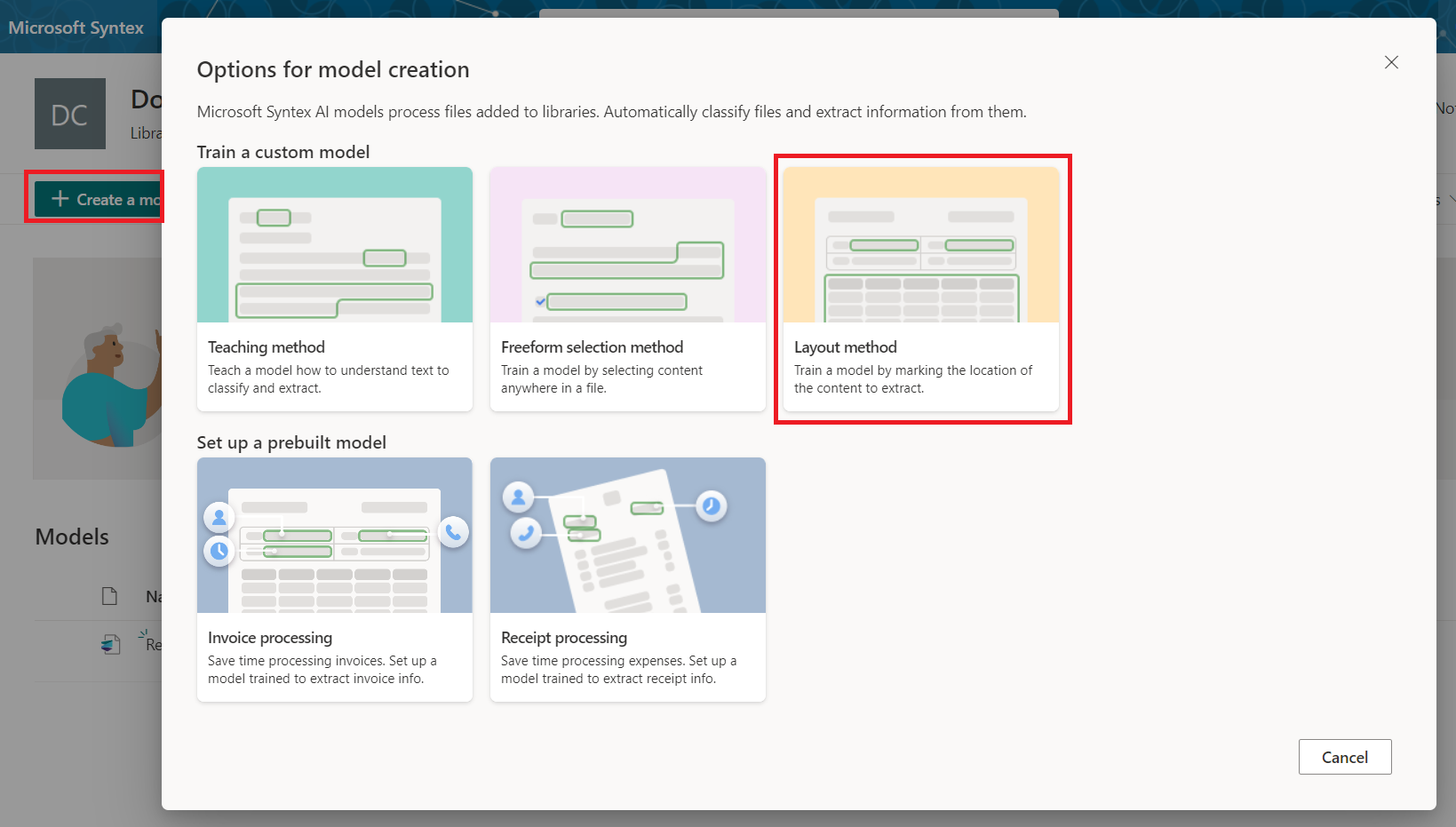
- Click Create a model.
-
Select the Layout method.
-
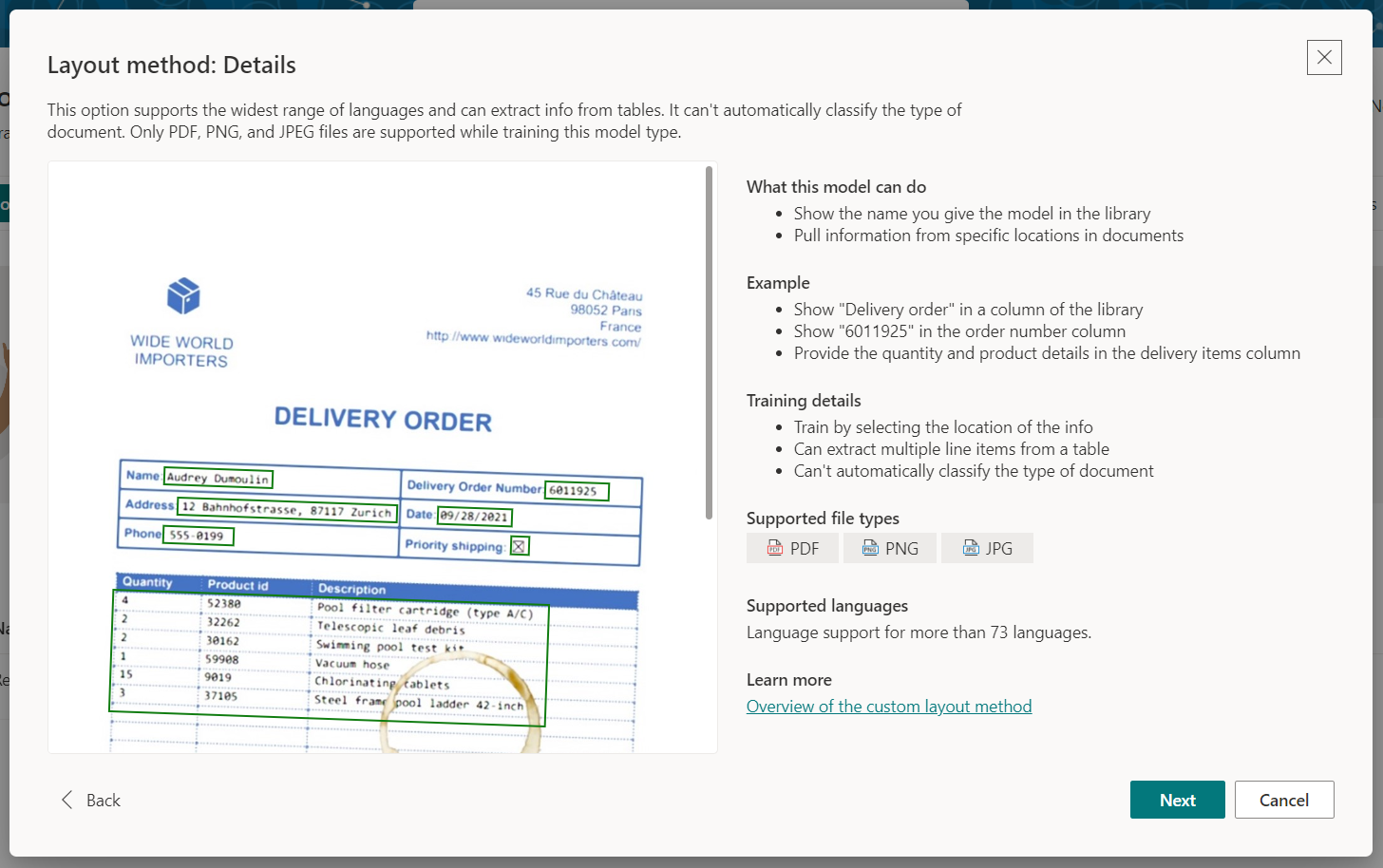
Read out the details to understand the model better. Note, you can use this model on PDF and image files and it does support more than 73 languages.
-
Name your model. Click Create.
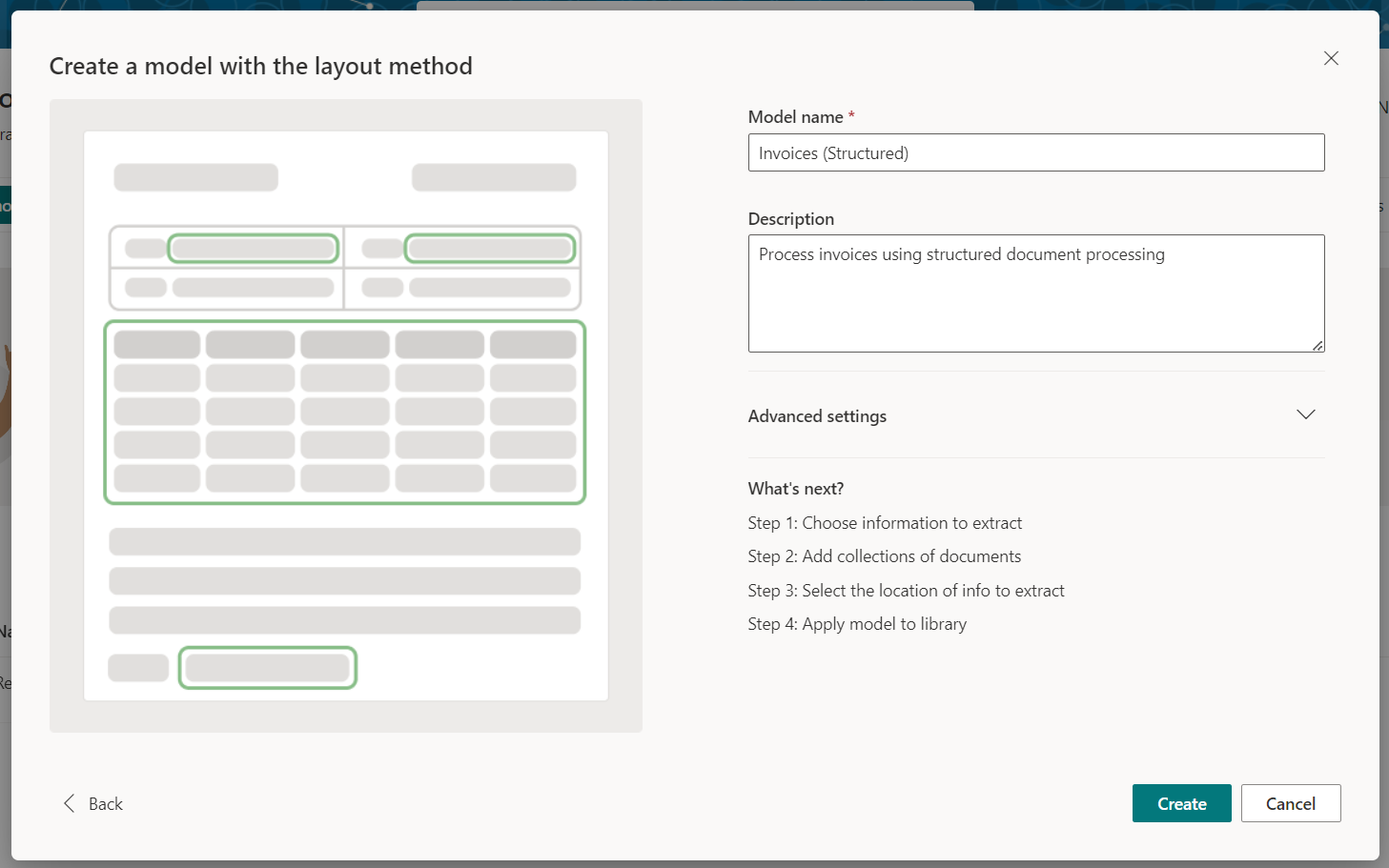
Choose information to extract
We can now start by defining the information to extract as Field, Checkbox, or Table. Based on the fields that we want to capture from the invoice, let us define the fields.
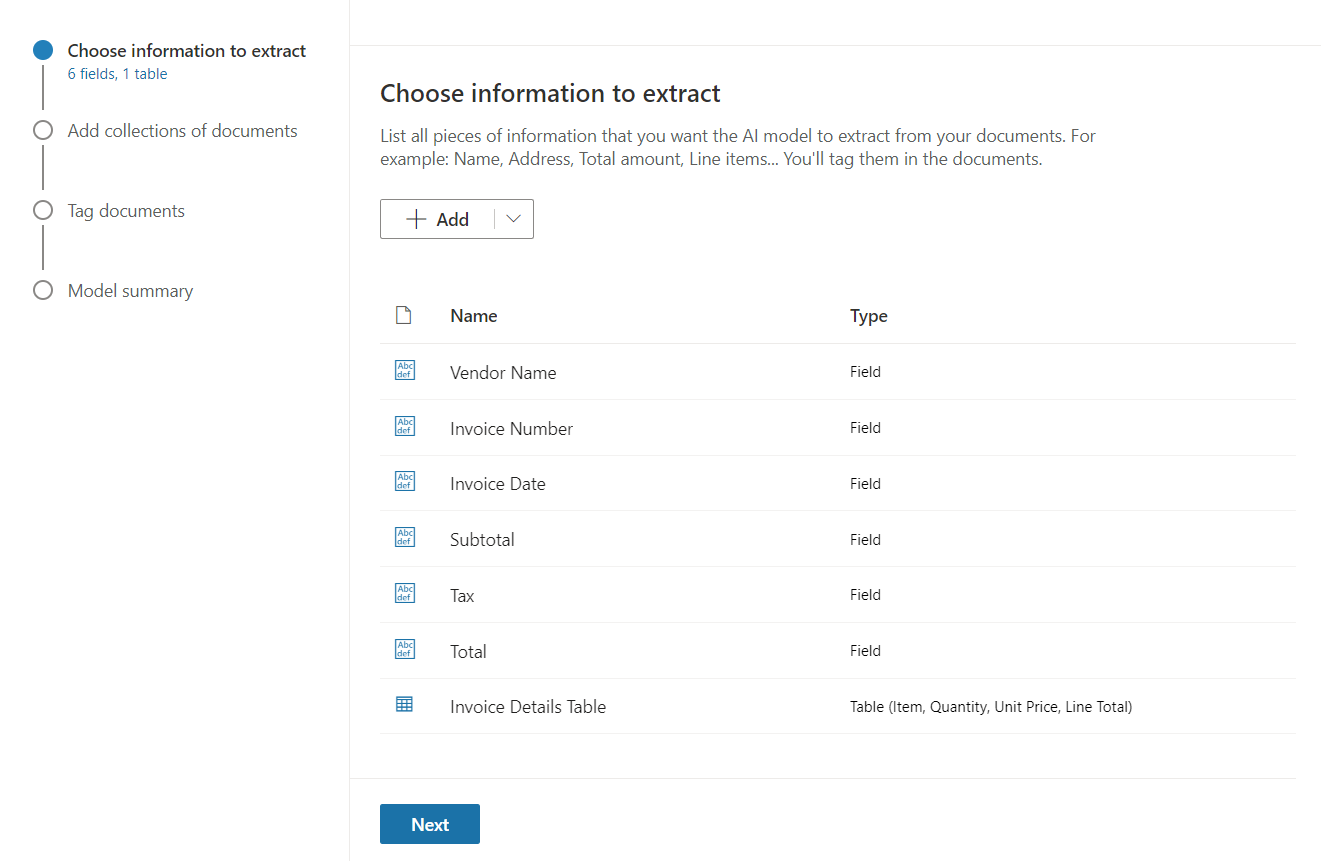
Add collections of documents
In the next step, we need to create a collection for each layout (e.g., Adatum and Contoso invoices).

We can add documents from any of below source:
- Local device
- Feedback loop
- SharePoint
- Azure Blob Storage
We need to add at least 5 sample documents in total.
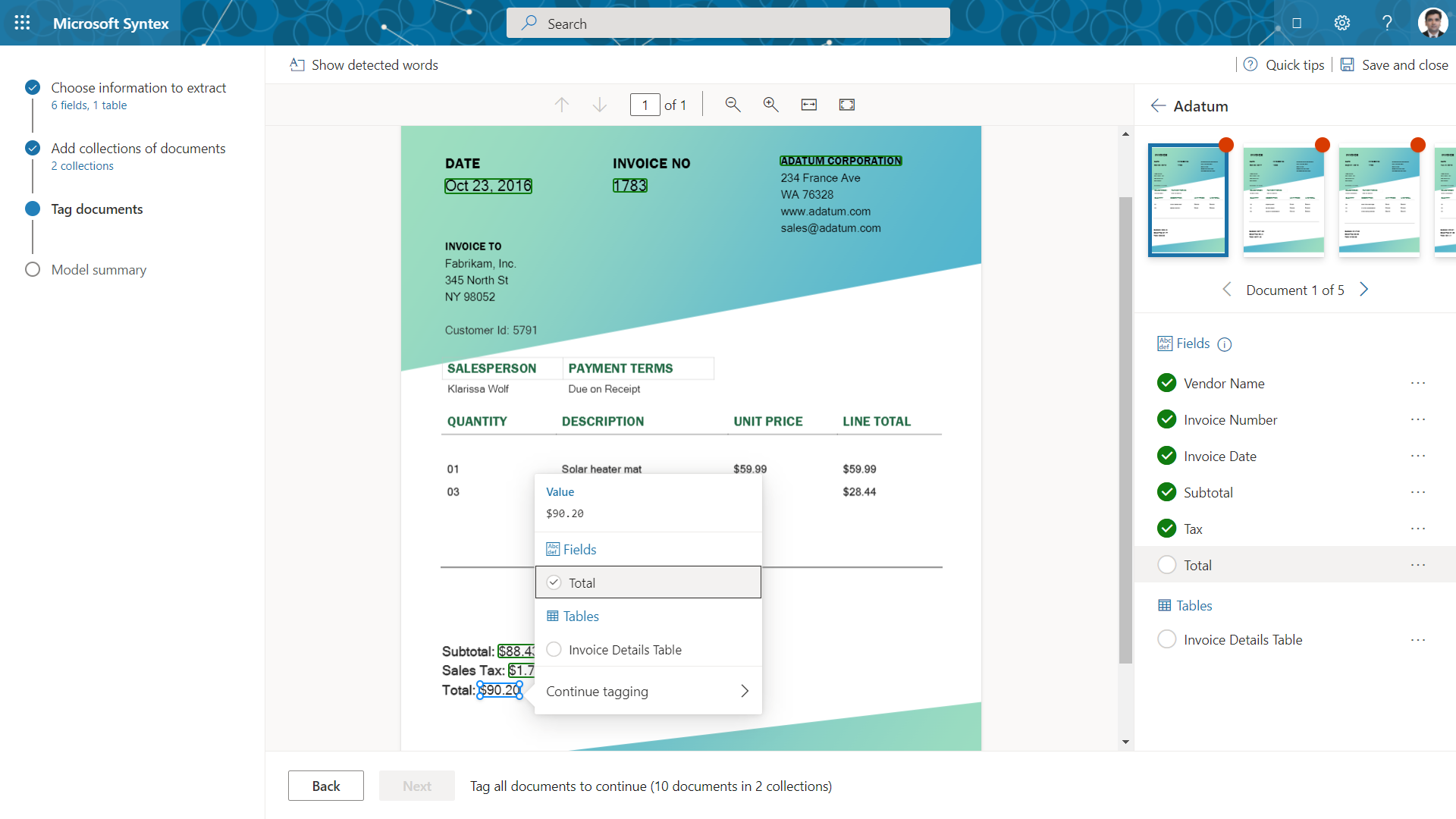
Tag documents
In the next step, we need to tag the documents to extract the information from the sample documents into the fields defined from each collection.
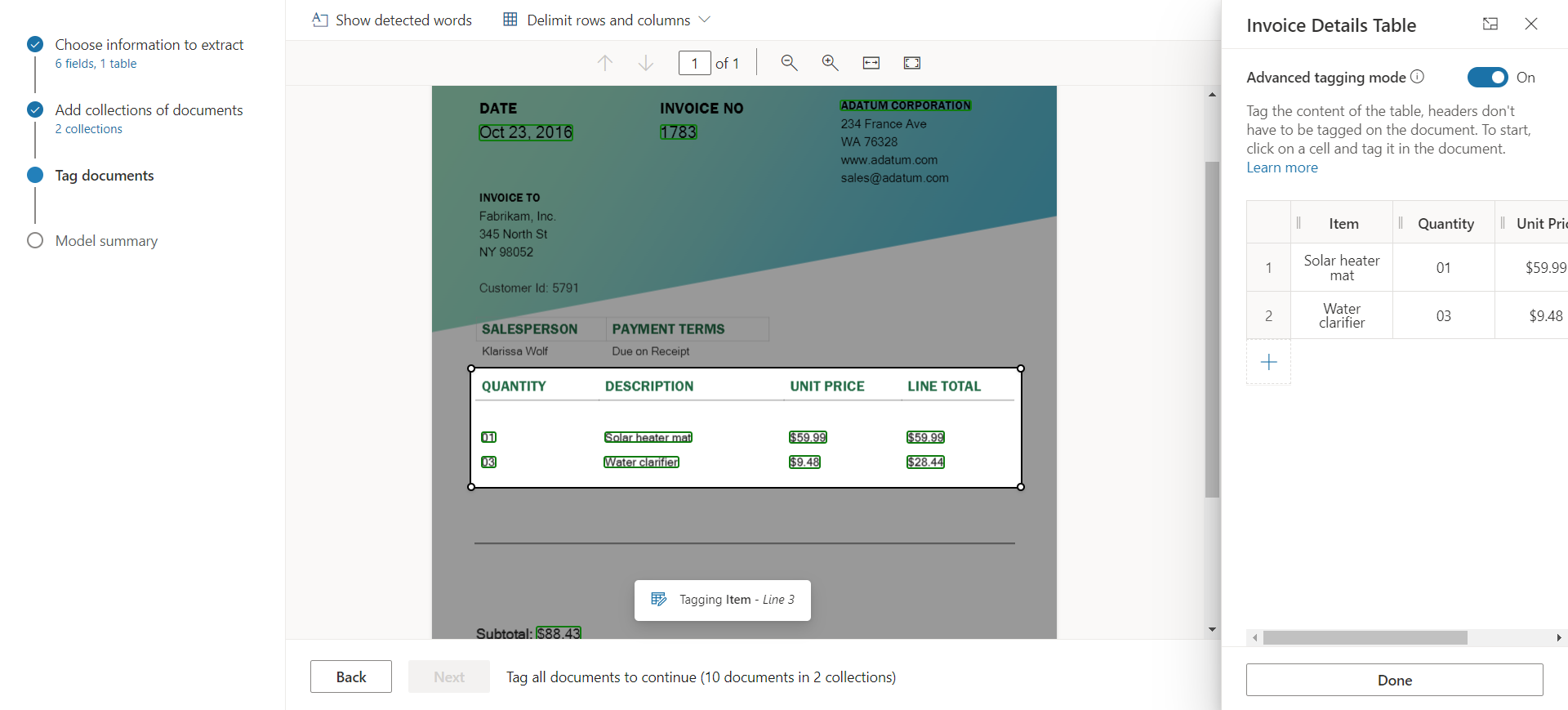
Processing the table involves defining the rows and columns. Or switch to advanced tagging mode to tag the content of the table.
Model summary
Review your model.
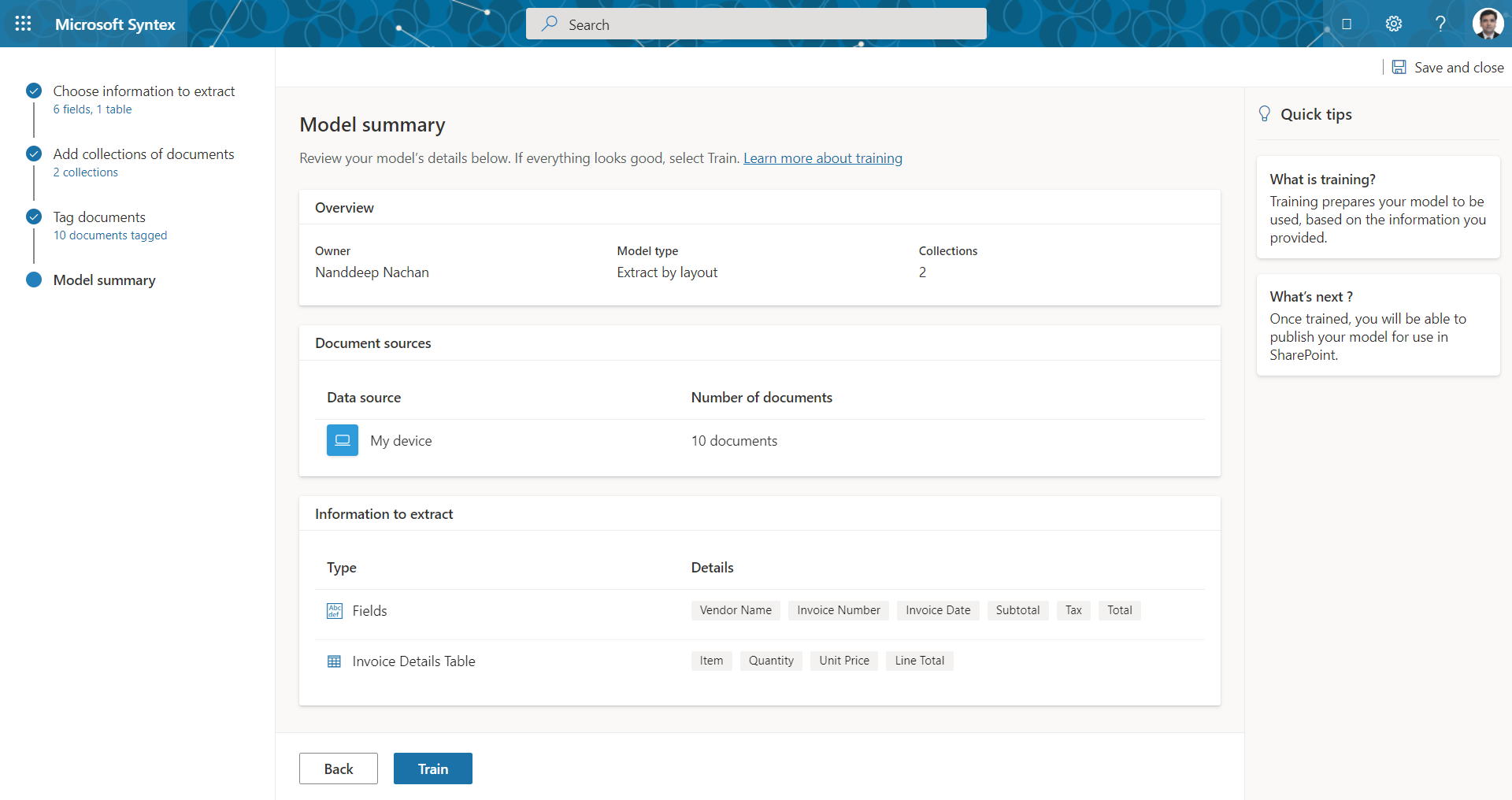
Train a model
Click Train to train your model. This may take from 20 minutes up to a few hours.
Publish trained model
After the training is complete, your model is ready to publish. It is a good idea to perform a Quick test before you go ahead and publish it.
Accuracy score of the model will show the correctly predicted percentage.
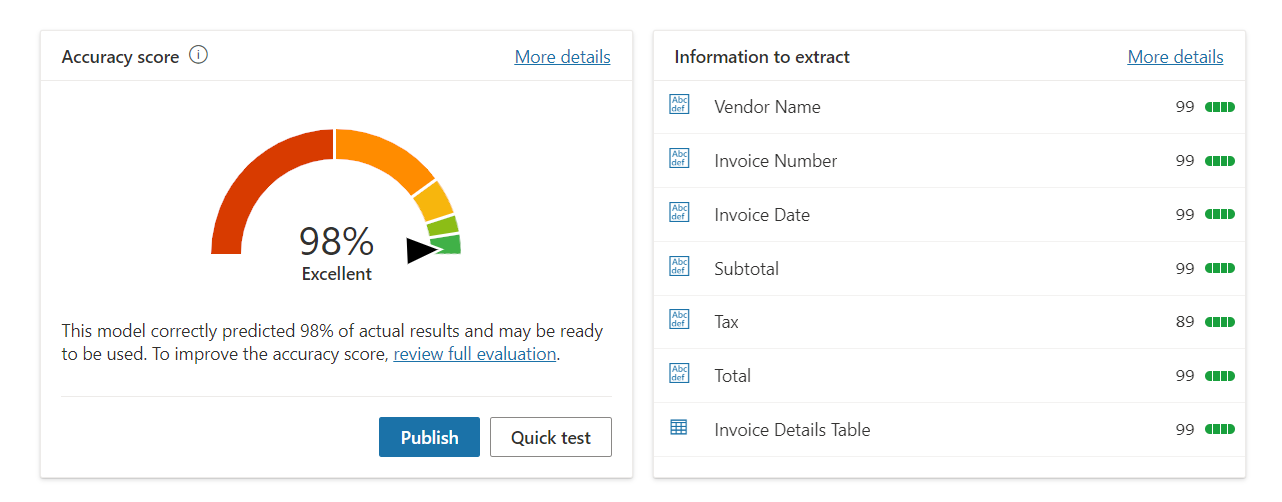
Click Publish to make the model available.
Apply the model
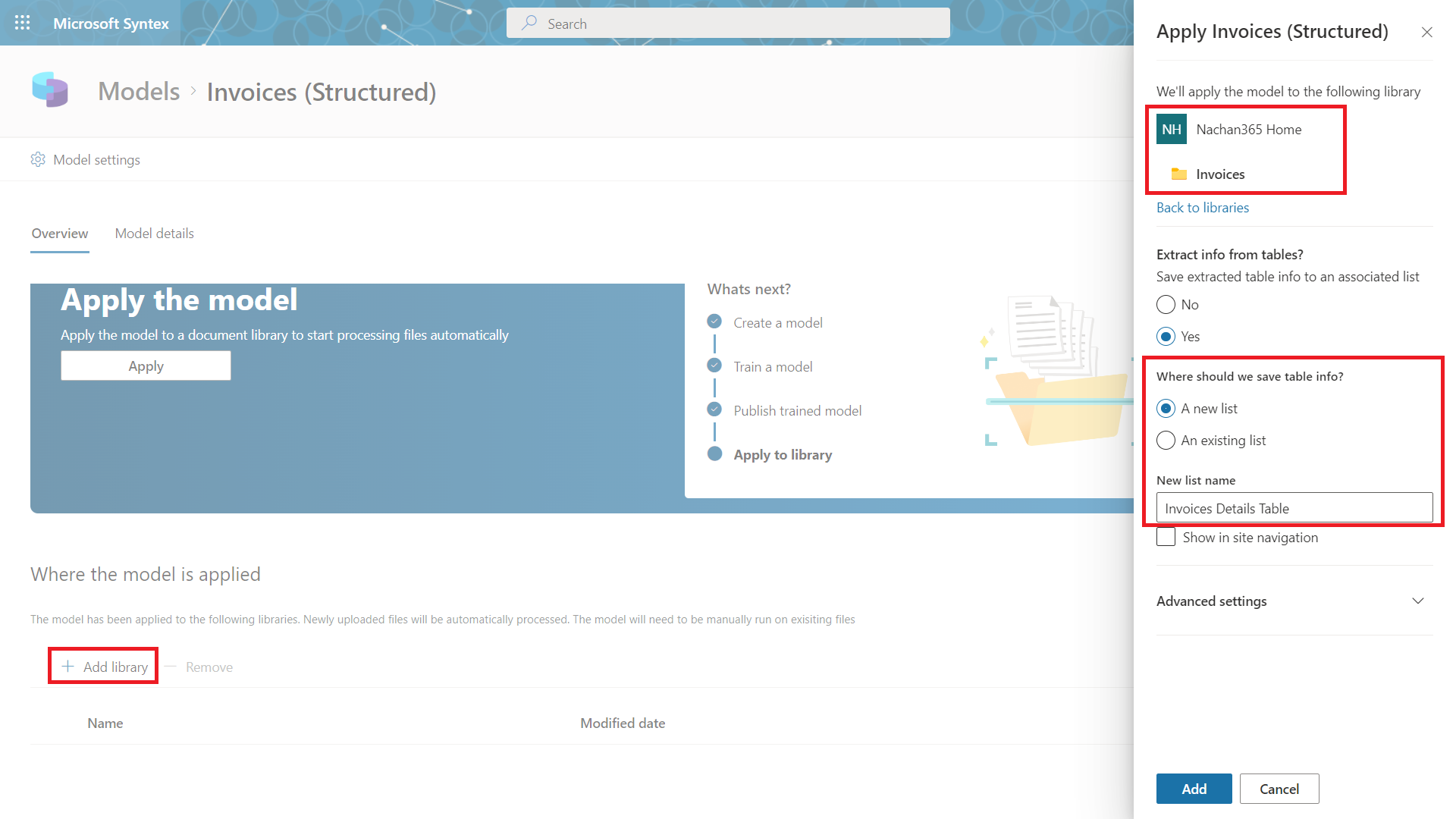
As a next step, we need to apply the model to a document library to start processing files automatically.
- Click + Add library
- Select SharePoint site and document library.
- If you choose to Extract info from tables , specify the SharePoint list.
End User Experience
Once the documents are uploaded to the designated document library, the custom model will be applied on it to extract the information.
Note: It takes around 30 minutes for Microsoft Syntex to extract the information from the documents by applying the custom models.
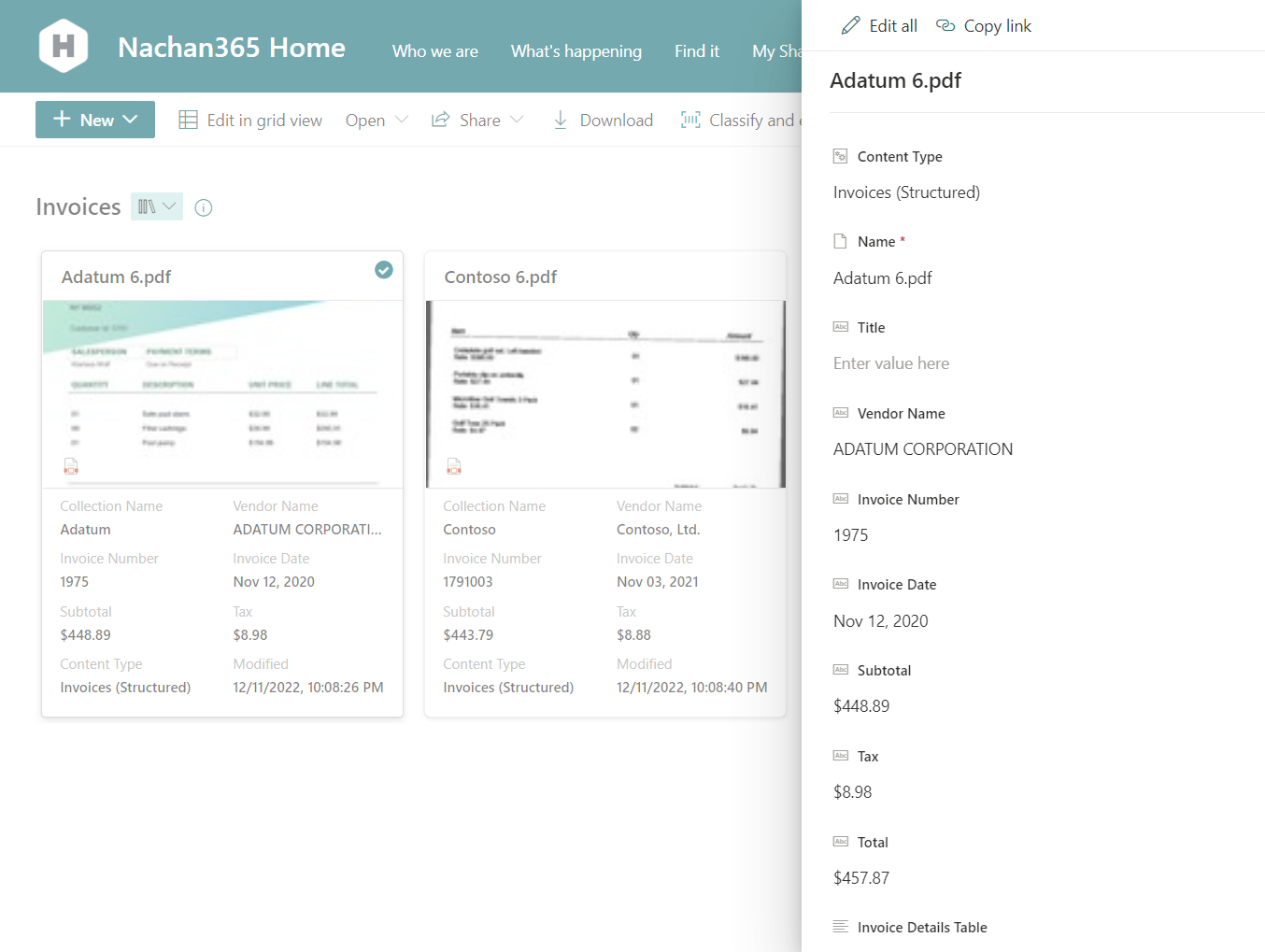
The result will look as follows:
The information from the table gets stored in a specified SharePoint list.
Summary
Structured document processing model works best for structured and semi-structured documents including forms and invoices. Structured document processing model helps to extract out the key-value pairs and table data from structured and semi-structured documents.



Leave a comment