
Freeform Document Processing with Microsoft Syntex

Overview
When your organization receives a huge number of documents over email, fax, or a physical copy, it is difficult to process them physically and classify the information. Freeform document processing as an AI offering of Microsoft Syntex makes your work easy in these situations.
This article is an extension to my previous article Getting started with Microsoft Syntex but focuses specifically on Freeform document processing.
Freeform document processing
The freeform selection method trains a model by selecting content anywhere in a file. This is helpful to extract information from unstructured and freeform documents. E.g., letters, contracts, etc. as information can appear anywhere in a document.
Freeform document processing model uses Microsoft Power Apps AI Builder to create and train models within Microsoft Syntex.
Business Scenario
Let us take a scenario, where we need to process the rental agreements in various formats. The information can appear in a freeform without any pre-defined layout.
You may use the Rental agreements sample data for setting up the model.

The above image shows two different formats of the rental agreement, but has common metadata to extract (E.g., Landlord, Tenant, Property Address, Start Date, End Date, Monthly Rent, and Security Deposit).
Create a Freeform document processing model
Follow the below steps to create a Freeform document processing model:
- Open the content center in SharePoint.
- From the top navigation, click Models.
- Click Create a model.
-
Select the Freeform selection method.
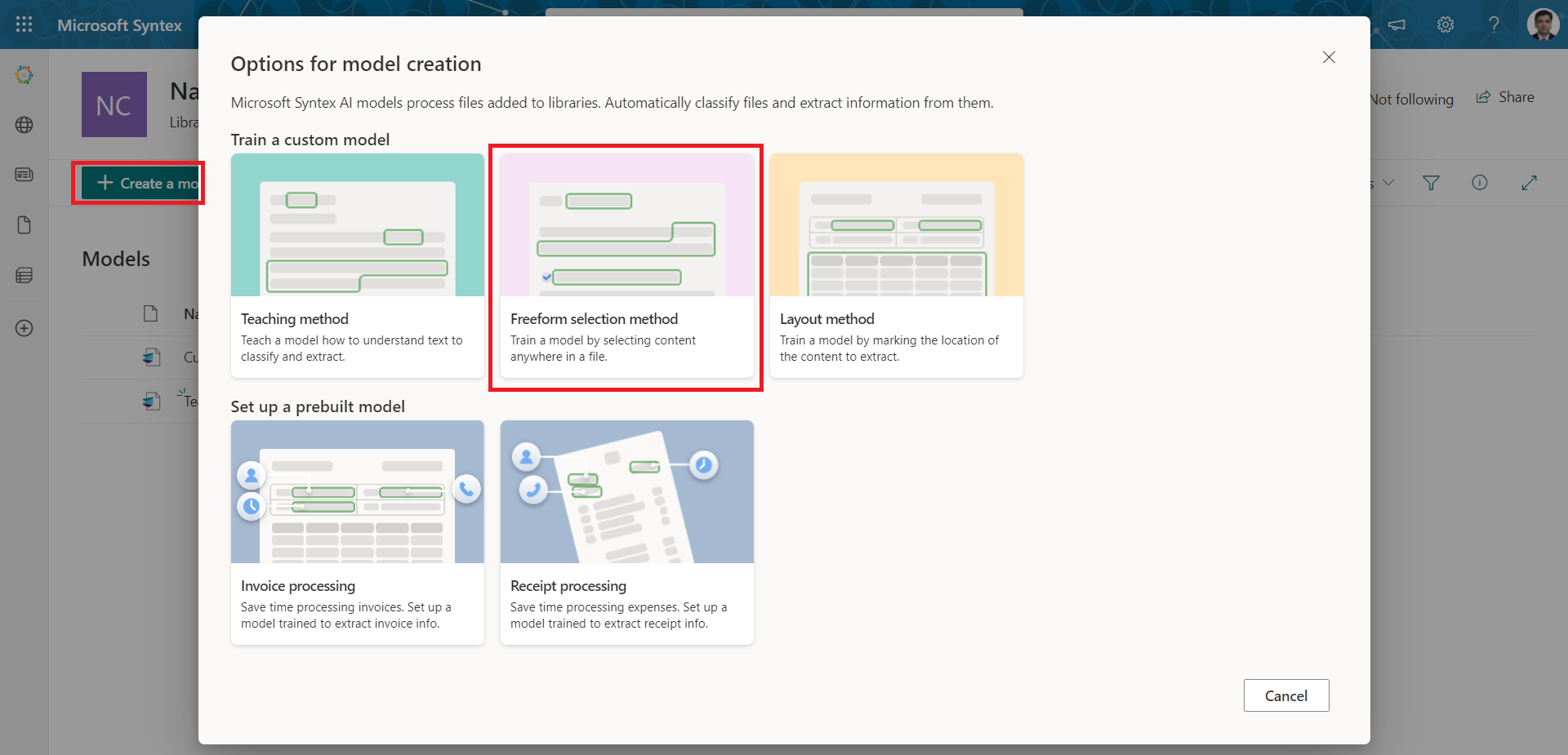
-
Read out the details to understand the model better. Note, you can use this model on PDF and image files in the English language.
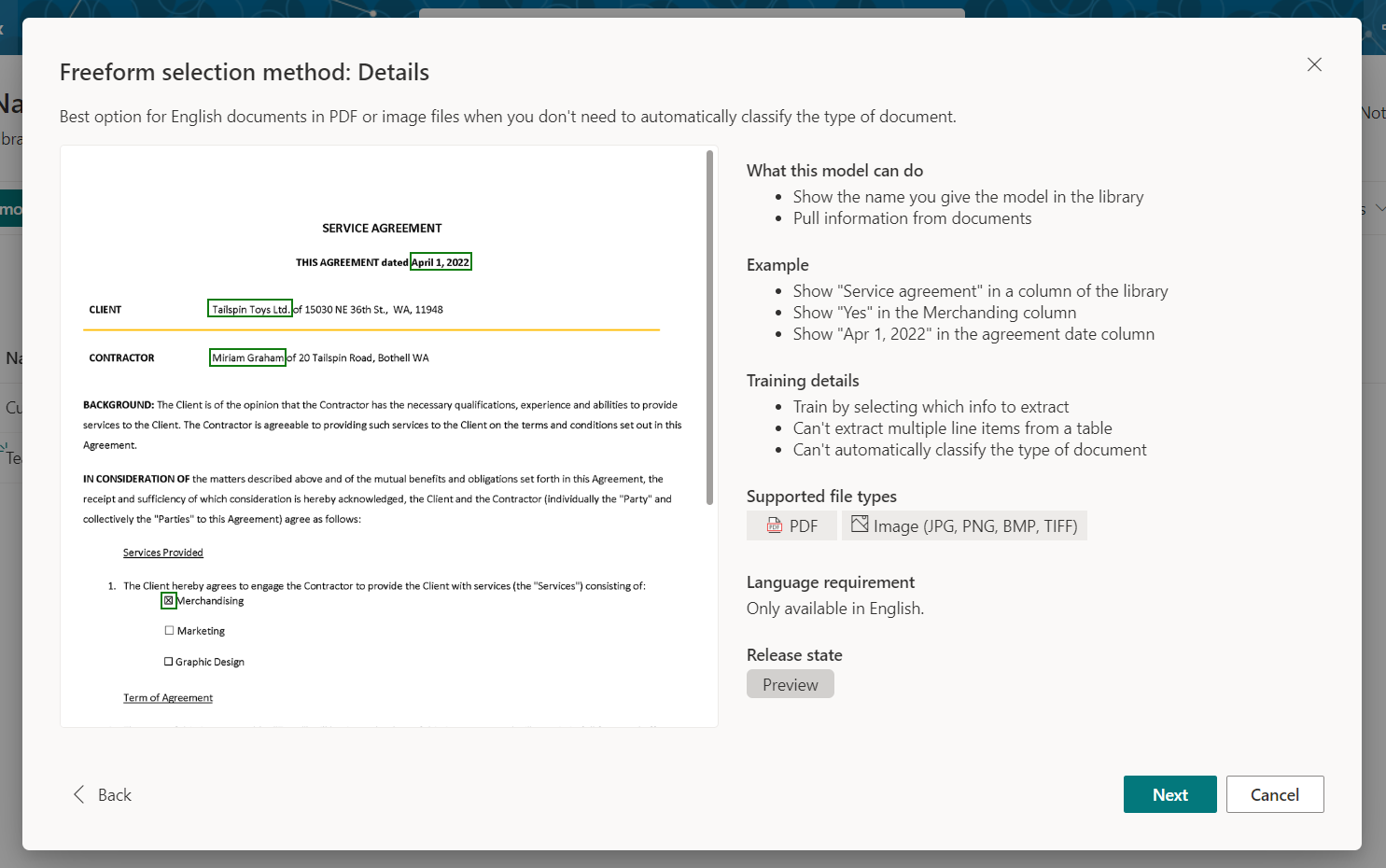
-
Name your model. Click Create.
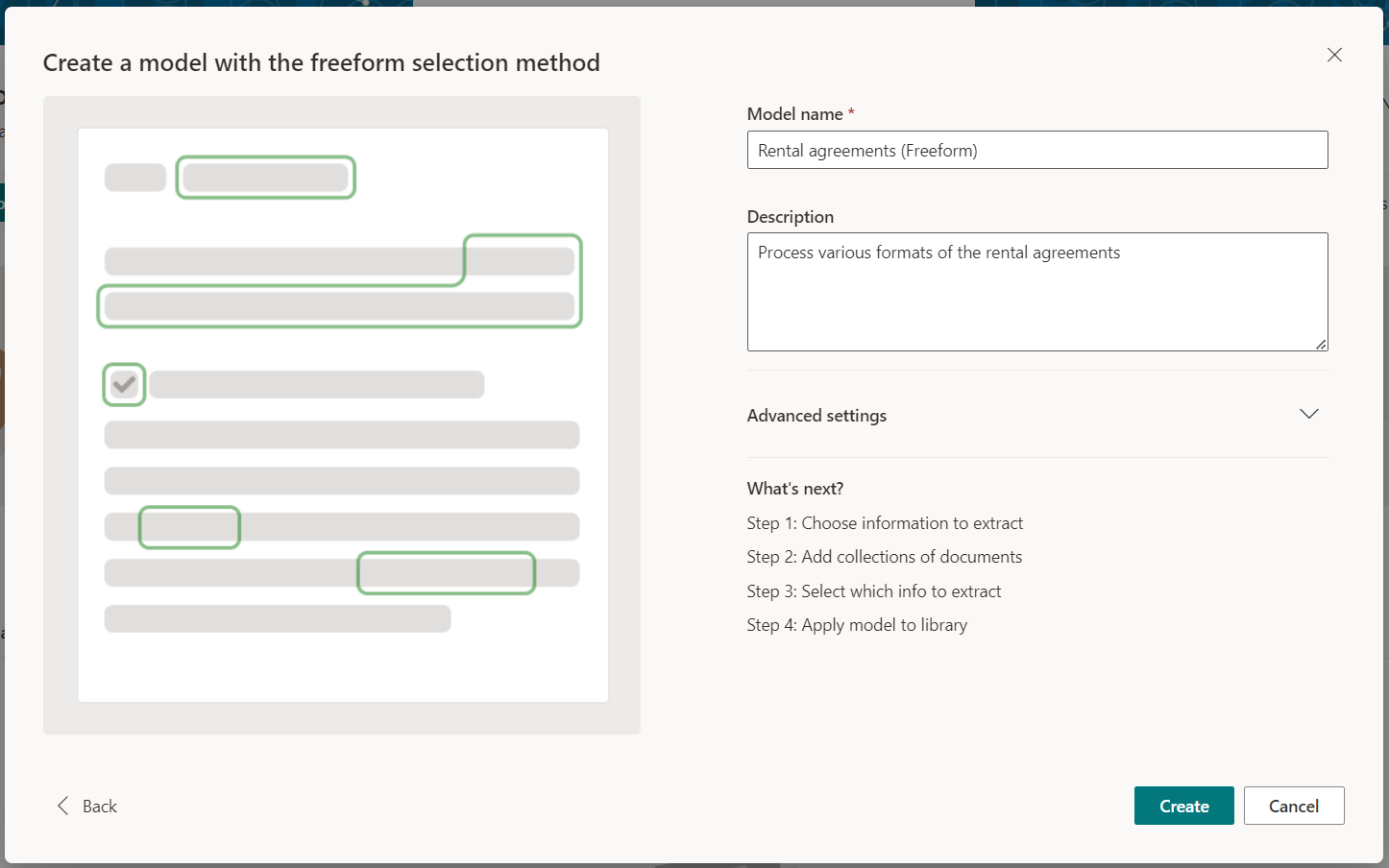
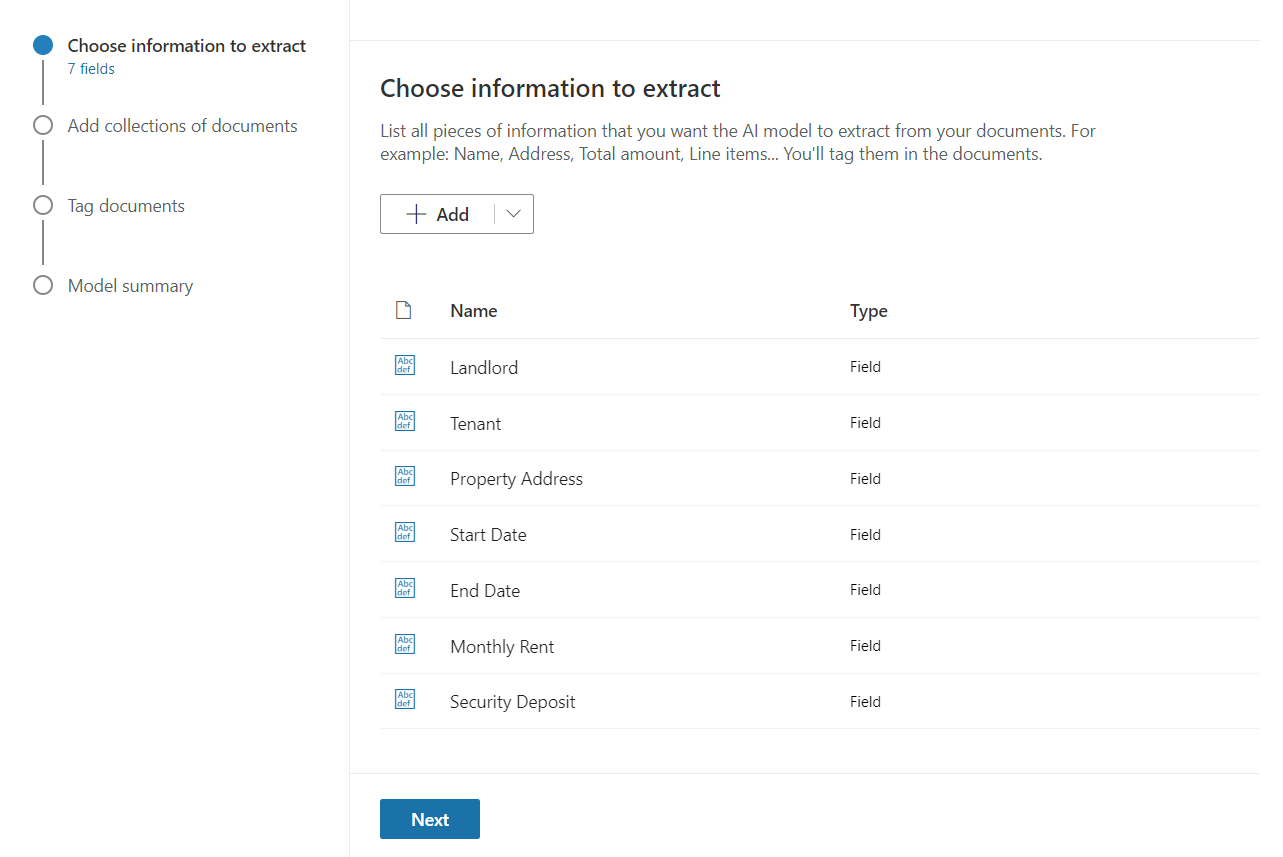
Choose information to extract
Based on the fields that we want to capture from the rental agreement, let us define the fields.
Add collections of documents
In the next step, we need to create a collection.
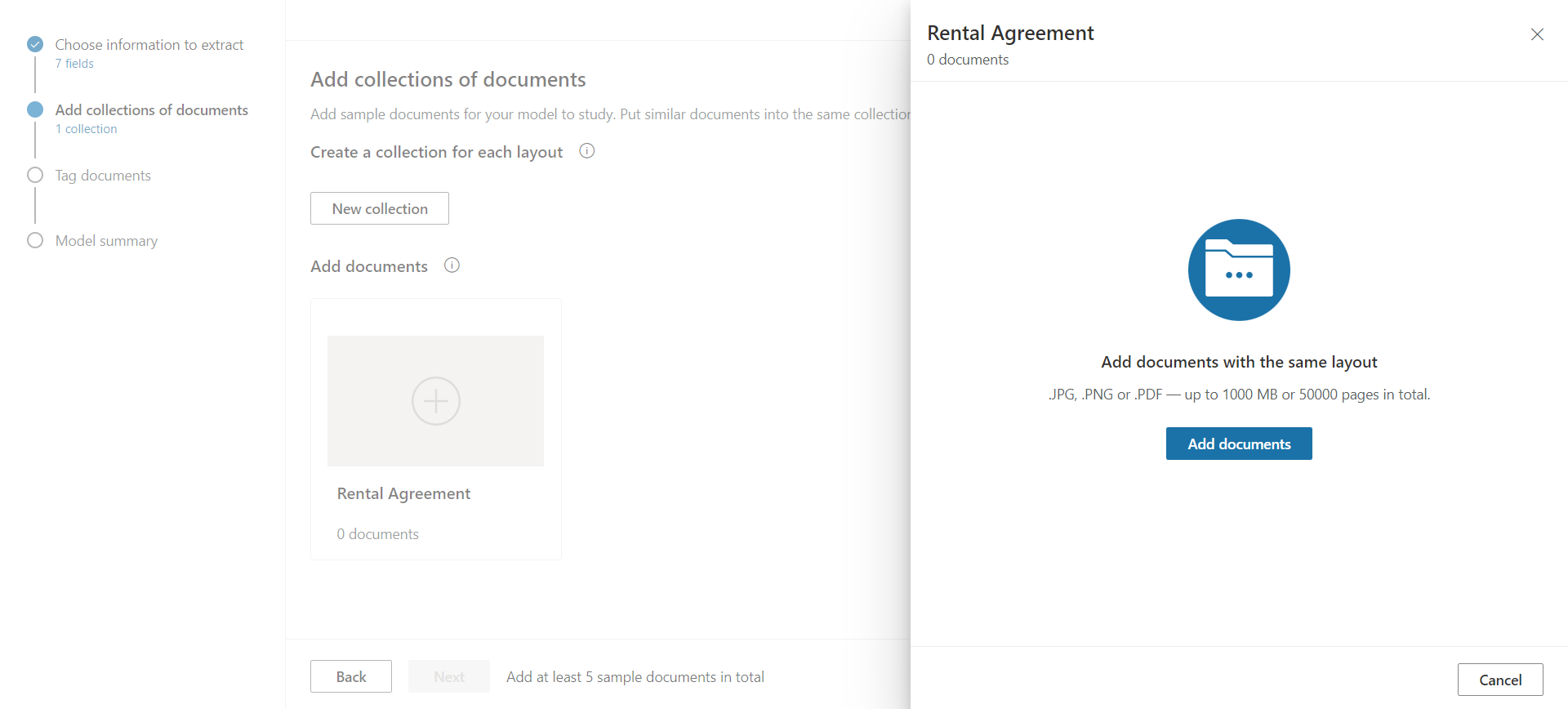
We can add documents from any of below source:
- Local device
- Feedback loop
- SharePoint
- Azure Blob Storage
Note: We need to add at least 5 sample documents in total.
Tag documents
In the next step, we need to tag the documents to extract the information from the sample documents into the fields defined.
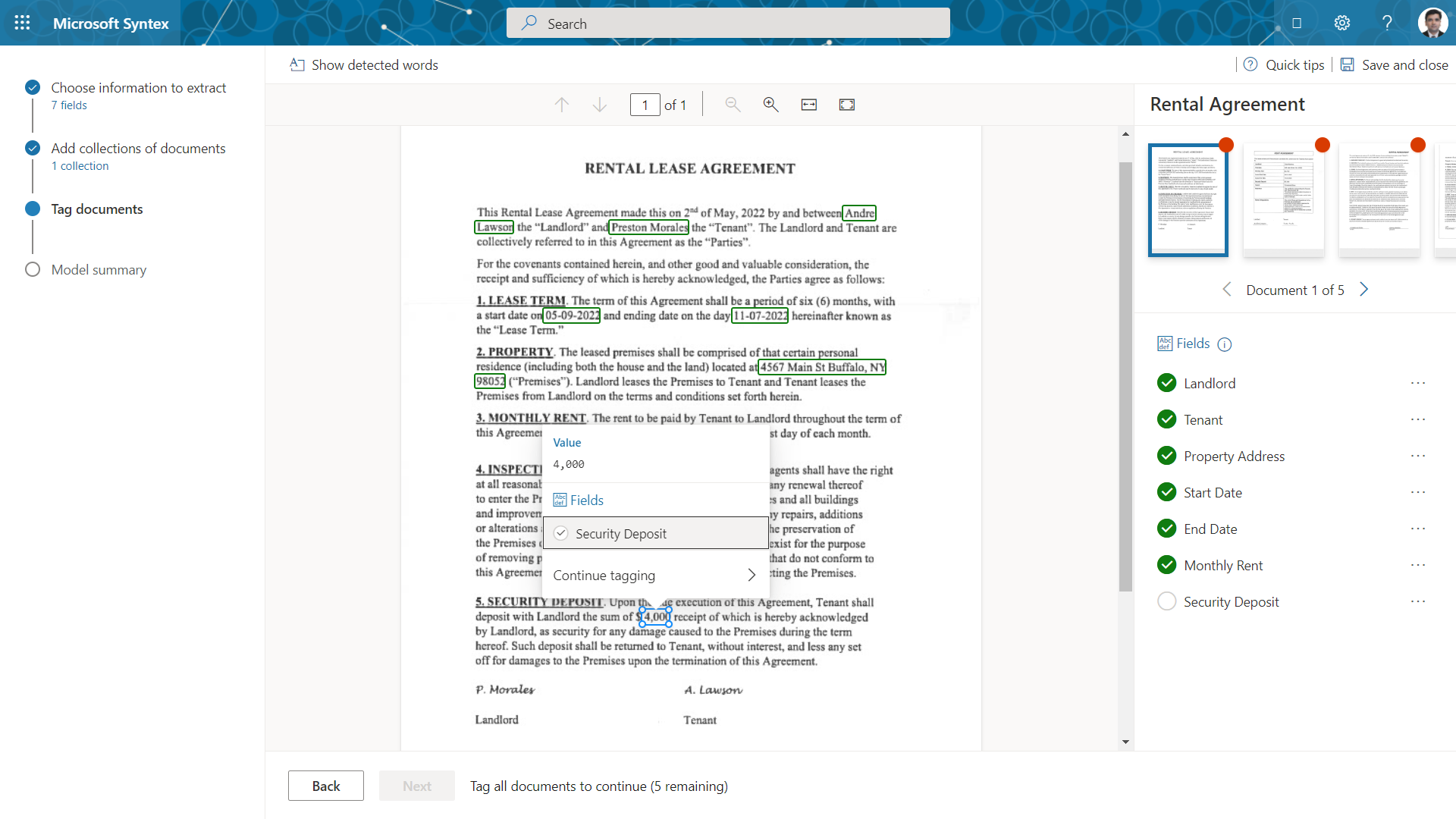
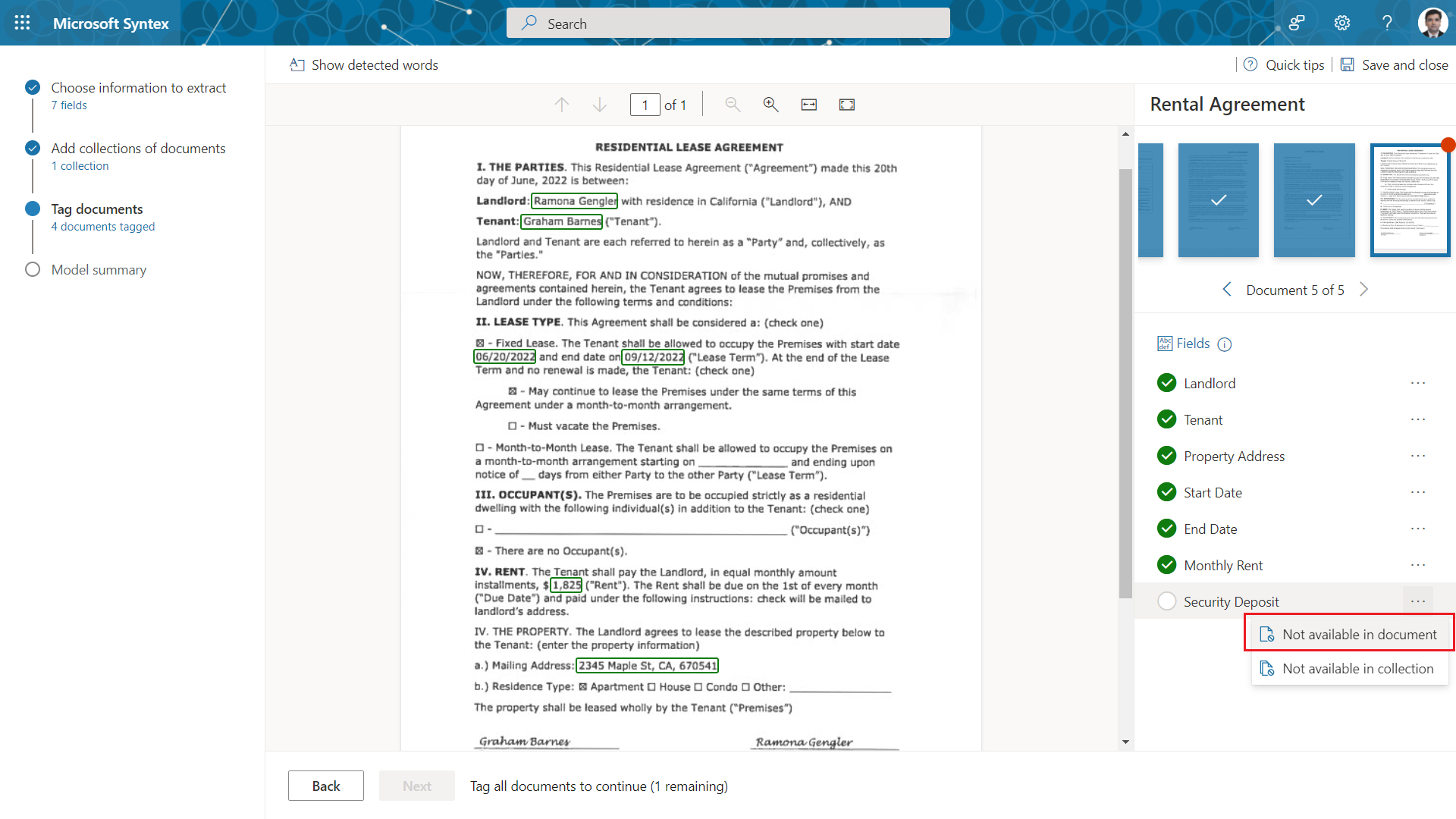
If any field is not available in a document to tag, select Not available in document against the field.
Model summary
Review your model.

Train a model
Click Train to train your model.
Note: This may take from 20 minutes up to a few hours, based on varied layouts.
Publish trained model
After the training is complete, your model is ready to publish. It is a good idea to perform a Quick test before you go ahead and publish it.
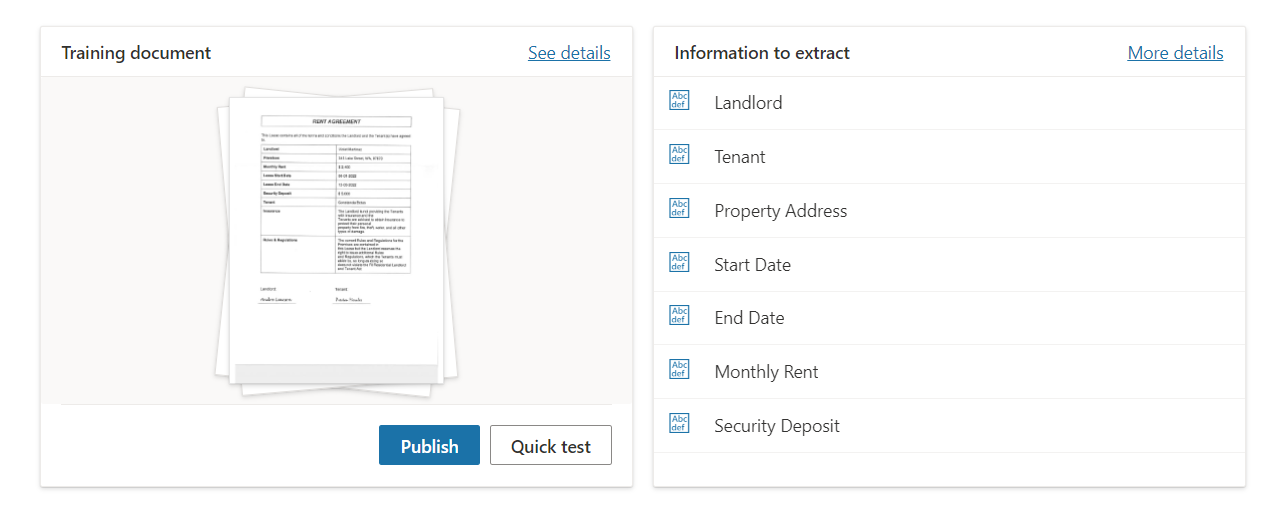
Click Publish to make the model available.
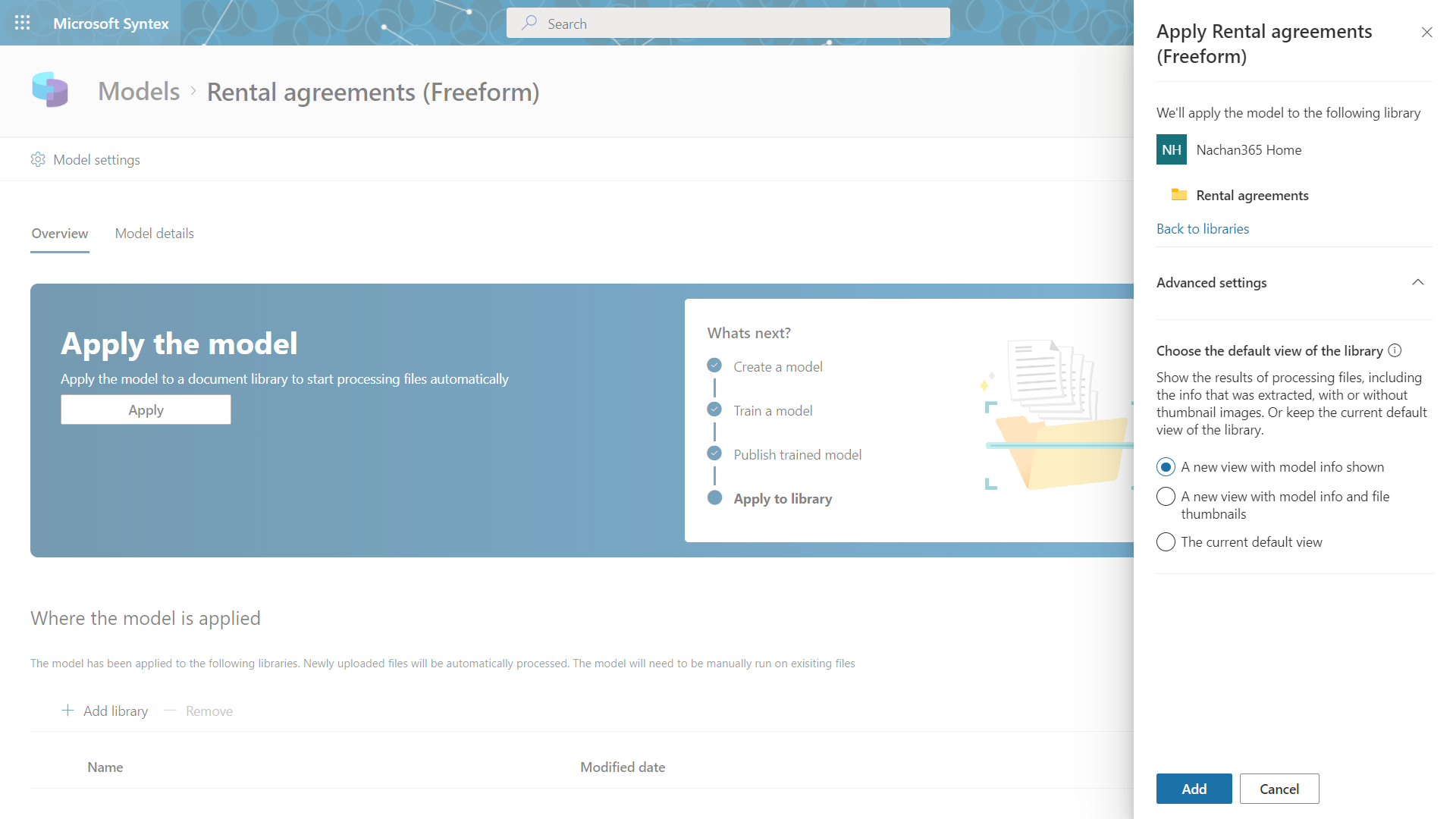
Apply the model
As a next step, we need to apply the model to a document library to start processing files automatically.
- Click + Add library.
-
Select SharePoint and document library.
End User Experience
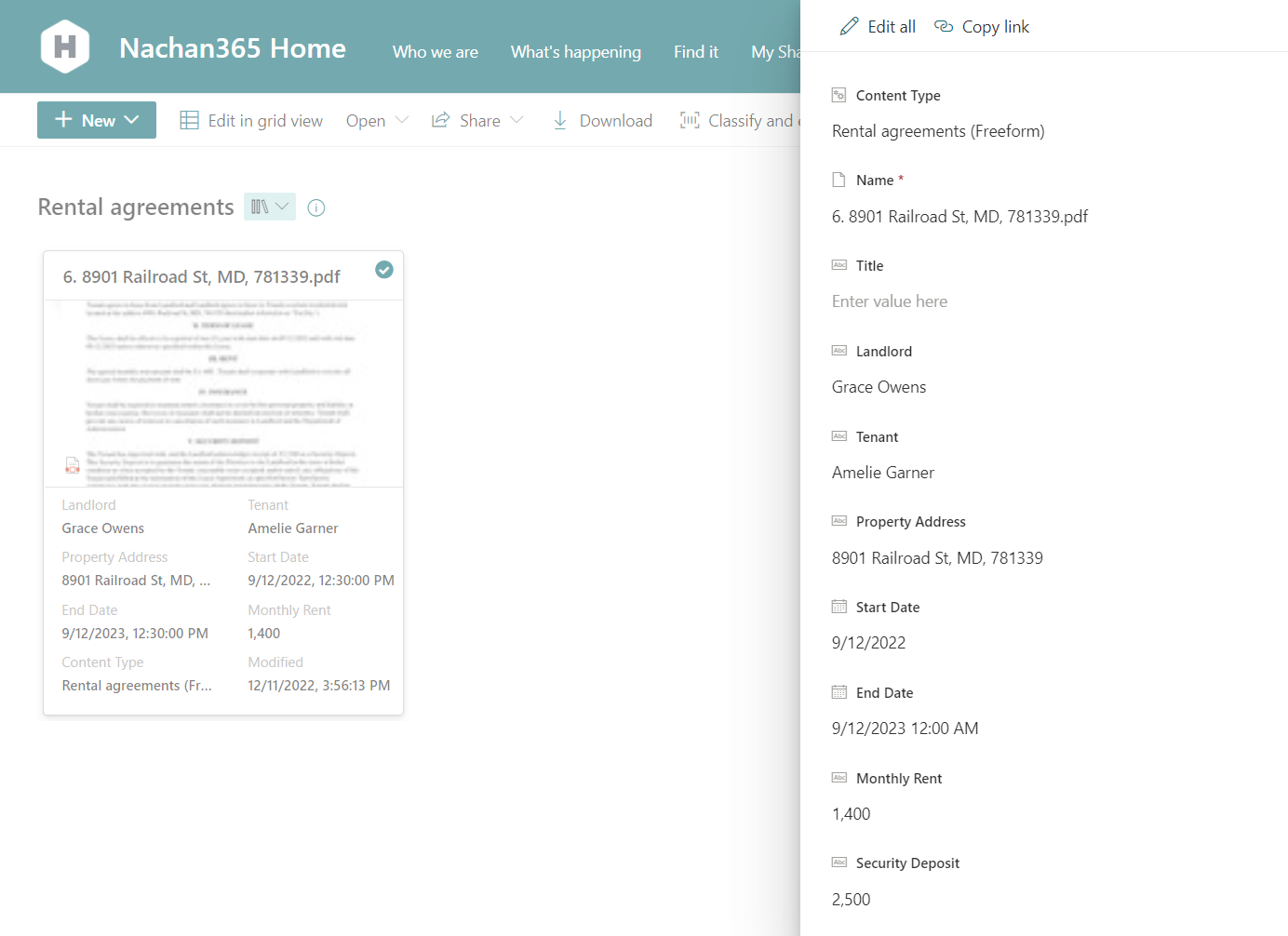
Once the documents are uploaded to the designated document library, select the documents, and click Classify and Extract.
Note: It takes around 30 minutes for Microsoft Syntex to extract the information from the documents by applying the custom models.
The result will look as follows:
Summary
Freeform document processing is an AI offering of Microsoft Syntex that makes it easy to extract information when an organization receives a huge number of documents over email, fax, or a physical copy.
Update
I came across another interesting article on the same topic - New Microsoft Syntex Freeform Document Processing Model & Syntex Model Renames by Leon Armston (MVP)
Leave a comment