
Enhancing AI responses with GraphRAG
Overview
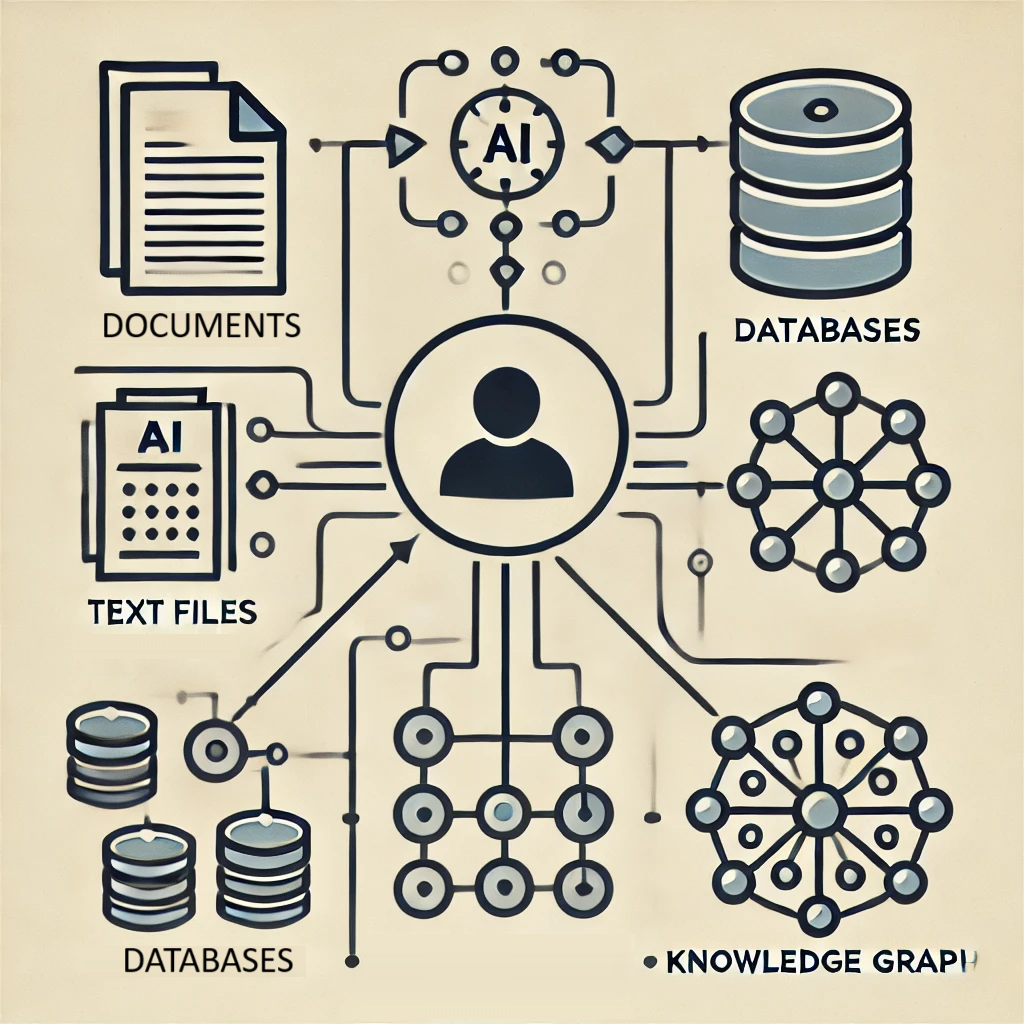
GraphRAG stands for Graph Retrieval-Augmented Generation. It enhances traditional Retrieval-Augmented Generation (RAG) by incorporating knowledge graphs. This approach leverages the interconnected data structure of knowledge graphs to provide richer, more accurate, and context-aware insights.
What is Retrieval-Augmented Generation (RAG)?
Before understanding GraphRAG, let’s look at Retrieval-Augmented Generation (RAG). RAG is a method that enhances AI models by allowing them to retrieve relevant, real-time information to assist with answering questions. Unlike traditional models, which rely only on what they have learned during training, RAG models can actively search for specific, fresh information to make their responses more accurate.
For example, if you ask a chatbot about a recent team update or document, a standard AI model might struggle if this data was not available during its training. With RAG, the model can pull information directly from relevant sources, enhancing its response with up-to-date information.
What Makes GraphRAG Different?
GraphRAG builds on the concept of RAG but takes it a step further by using structured data sources (e.g., files, databases, conversations) as a key part of the retrieval process. It retrieves the most relevant information and feeds it to the AI, enabling answers based on both static knowledge and dynamic, real-time information.
The result is an AI system that doesn’t just answer general questions but gives context-specific answers based on the latest data available in connected sources.
Getting Started with GraphRAG
Set Up Your Environment:
Install GraphRAG with below command:
pip install graphrag
Run the indexer
Run the below command to get a dataset ready
mkdir -p ./ragtest/input
Add your data
GraphRAG uses a more sophisticated method for retrieving and augmenting data compared to traditional RAG approaches, which often rely on unstructured text data.
As of today, GraphRAG supports only text files. If you have PDF files, you can use below Python code to convert your PDF files to TXT. If the file contains image it extracts text from image using OCR.
This script iterates through all PDF files in a specified folder, extracts their text content, and saves it to a .txt file with the same name.
pip install PyPDF2 pdf2image pytesseract # One time installation
import os
from PyPDF2 import PdfReader
from pdf2image import convert_from_path
import pytesseract
# Set the tesseract path
pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
def pdf_to_text(pdf_path, txt_path):
try:
reader = PdfReader(pdf_path)
text_content = ""
# Extract text using PyPDF2 for regular PDFs
for page in reader.pages:
text = page.extract_text()
if text:
text_content += text
else:
# If no text found, use OCR
print(f"No text found on page, using OCR for {pdf_path}.")
images = convert_from_path(pdf_path, 500, poppler_path=r'C:\Git\graphrag-contracts\poppler-24.08.0\Library\bin')
for image in images:
text_content += pytesseract.image_to_string(image)
with open(txt_path, 'w', encoding='utf-8') as text_file:
text_file.write(text_content)
print(f"Converted {pdf_path} to {txt_path}")
except Exception as e:
print(f"Error processing {pdf_path}: {e}")
def convert_all_pdfs_in_folder(folder_path):
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
pdf_path = os.path.join(folder_path, filename)
txt_path = os.path.join(folder_path, filename.replace('.pdf', '.txt'))
pdf_to_text(pdf_path, txt_path)
# Replace 'your_folder_path' with the path to the folder containing your PDF files
convert_all_pdfs_in_folder('your_folder_path')
print("All PDFs in folder converted to text")
To start with add you data files under /ragtest/input folder. For the demonstration purpose, I have added few travel brochures under the input folder.
Initialize workspace
To start using GraphRAG, you must generate a configuration file. Run below command:
graphrag init --root ./ragtest
This will create two files: .env and settings.yaml in the ./ragtest directory.
-
In
.envfile, Set theGRAPHRAG_API_KEYvalue with Azure OpenAI key.GRAPHRAG_API_KEY=<API_KEY> -
Update
settings.yamlby replacing placeholders with LLM and embedding model names.
Running the Indexing pipeline
Execute below command:
graphrag index --root ./ragtest
Using the Query Engine
Now, let us ask some questions using this dataset.
Example 1: Global search to ask a high-level question
graphrag query --root ./ragtest --method global --query "How many hotels do we have?"

Example 2: Local search to ask a more specific question
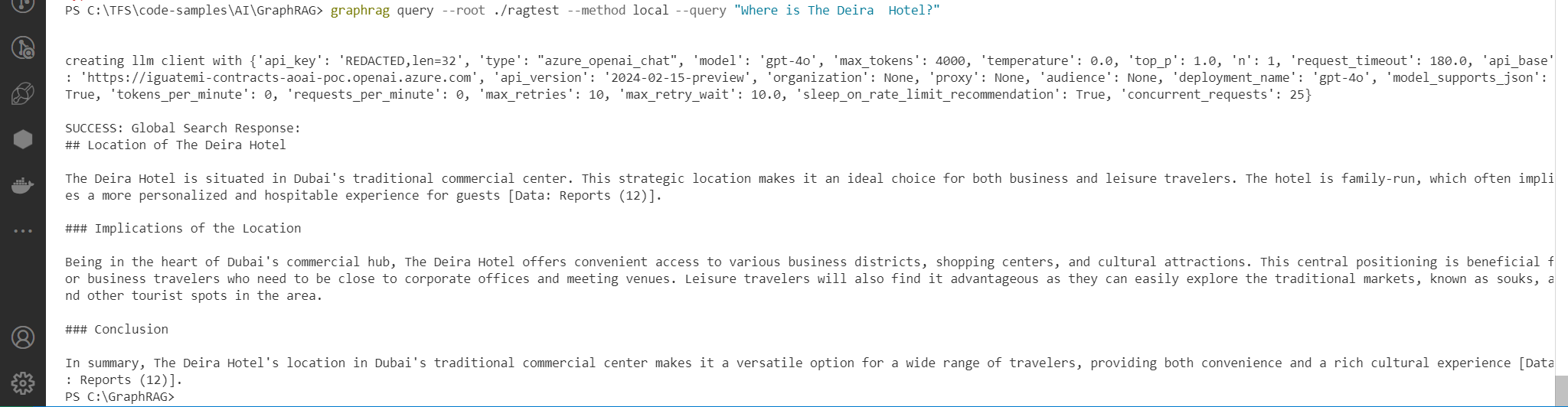
graphrag query --root ./ragtest --method local --query "What are the hotel recommendations in Dubai?"
GraphRAG vs. Baseline RAG
Retrieval-Augmented Generation (RAG) enhances language model (LLM) outputs by incorporating real-world information. Typically, RAG methods use vector similarity as a baseline search approach (Baseline RAG). However, Microsoft Research’s GraphRAG improves performance by incorporating knowledge graphs, which help LLMs reason about complex information.
RAG is particularly useful for querying private datasets—proprietary business data or documents that LLMs haven’t been trained on. While Baseline RAG is designed to address this, it can struggle in certain areas:
- It has difficulty synthesizing insights when the answer requires connecting diverse information sources.
- It performs poorly in understanding and summarizing broad semantic concepts within large data collections or documents.
GraphRAG addresses these limitations by creating a knowledge graph from the input data, using graph machine learning outputs and community summaries to enhance the query process. This approach significantly improves performance on complex questions, setting a new standard for private dataset reasoning.
Limitations
- Supported file types: Only text files are supported.
- Time to run Indexing pipeline: For large number of files (> 1000) the time taken to run indexing pipeline is very long (even up to a day).
- Delta update: Even for a smaller change in any file, we need to re-run the entire indexing pipeline.
- Performance: Query performance can degrade with extremely large datasets if not managed properly.
Summary
GraphRAG represents a powerful fusion of graph databases and AI, offering significant improvements over traditional RAG systems in terms of contextual accuracy, adaptability, and scalability. While it comes with its complexities and challenges, the benefits it provides in enhancing AI-generated content make it a valuable tool for various industries.
References
Code Download
The code developed during this article can be found here.
Leave a comment