
Azure AI Search on Structured and Non-Structured Content
Overview
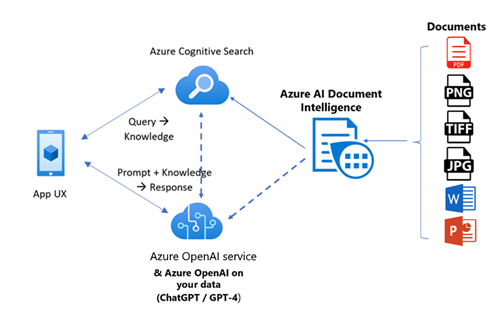
This article outlines the technical architecture for implementing an Azure AI Search solution that indexes contracts stored as PDF files. These files contain both structured and unstructured content, primarily as images. The solution converts these images to searchable text using OCR (Optical Character Recognition), builds a search index using Azure Cognitive Search, and answers queries based on the contract data using AI-driven Q&A functionality.
Approach
To build an index in Azure AI Search for answering questions based on PDF files with both structured and unstructured content (in the form of images), you can follow these steps:
Step 1: Convert PDF to Searchable Text
Since the content of the PDFs is in image form, you will first need to convert the images into text. Use Azure Cognitive Services to perform Optical Character Recognition (OCR) on the PDFs:
- Azure Form Recognizer: Extracts text from structured and unstructured documents, providing key-value pairs, tables, and more.
- Azure Cognitive Services OCR: Converts the images in the PDFs to searchable text.
Step 2: Preprocess the Content
Once the OCR process extracts the text, you may need to:
- Clean the data (remove noise, irrelevant information, etc.).
- Structure the text if it’s unstructured by classifying the content.
- Normalize different contract formats for consistency.
Step 3: Index the Documents in Azure Cognitive Search
After preprocessing, you can use Azure Cognitive Search to index the text. Steps include:
- Data Source: Define the data source, which will be the OCR-extracted text.
- Indexer: Create an indexer to automatically extract the data from the source.
- Index: Design an index schema that supports the types of queries you expect (text search, filters, etc.).
- Skills (Optional): Add AI enrichments to enhance search functionality (e.g., extract key phrases, detect entities, or summarize content).
Step 4: Enrich the Search with Cognitive Skills
Azure Cognitive Search supports the integration of Cognitive Skills that enhance the indexing process by extracting metadata and information from the documents:
- Use Text Analytics to extract entities like names, dates, and legal terms.
- Implement Custom Skills for custom processing logic, such as identifying critical sections in contracts.
Detailed Architecture Flow
1. Data Ingestion
- Step 1.1: Contracts in PDF format are uploaded to Azure Blob Storage.
- Step 1.2: An Azure Logic App or Azure Function triggers when a new file is uploaded and sends the file for OCR processing.
2. OCR and Preprocessing
- Step 2.1: PDF files are passed through Azure Cognitive Services OCR or Form Recognizer to extract text from images and structured fields.
- Step 2.2: The extracted text is stored back into Azure Blob Storage in JSON or other suitable formats.
3. Cognitive Search Indexing
- Step 3.1: An indexer automatically pulls the extracted text from Azure Blob Storage into the Azure Cognitive Search index.
- Step 3.2: During the indexing process, AI enrichment (via Cognitive Skills) is applied to enhance the searchable data (e.g., entity recognition, key phrase extraction).
4. Q&A and Search Integration
- Step 4.1: Users can interact with the search engine through a web/mobile app or Teams.
- Step 4.2: The app sends the query to the Azure Search API.
- Step 4.3: For question-answering, the query is sent to Azure OpenAI to provide relevant answers based on the contract data.
Handling Structured and Unstructured Content
1. Handling Structured Content
Structured content refers to data in a well-defined format, such as tables, forms, or labeled fields (e.g., parties involved, dates, or pricing terms) commonly found in contracts.
Process Overview:
- Step 1: Extracting Structured Data using OCR/Form Recognizer
- Azure Form Recognizer is optimized for extracting structured content from documents.
- When the PDF contains images of forms or tables, Form Recognizer identifies key-value pairs, table structures, and other layout-based elements.
- Form Recognizer will extract each of these values and label them appropriately.
- Step 2: Storing and Indexing Structured Data
- After extraction, the structured data is stored as labelled fields (e.g., “Client Name,” “Contract Date,” “Total Amount”) in Azure Blob Storage.
- This data is indexed using Azure Cognitive Search. Each field is treated as a separate entity, enabling precise searches. For example, users can search for contracts by “Client Name” or “Contract Date” using these indexed fields.
- Step 3: Query and Search
- With the data indexed, users can perform structured queries. For example, they might search for contracts from a specific client by name or filter by contract date.
- This structured indexing allows for filtering, faceting, and precise searches across specific fields in the contract.
2. Handling Unstructured Content
Unstructured content includes free-text paragraphs, clauses, or sections that don’t follow a strict format (e.g., the body of the contract or legal terms written in paragraph form).
Process Overview:
- Step 1: Extracting Unstructured Data using OCR
- For the unstructured portions of the contract (which may consist of paragraphs of text or images of printed text), Azure Cognitive Services OCR is used to extract raw text.
- OCR will convert this image-based text into machine-readable text.
- Step 2: Text Preprocessing
- Once the text is extracted, it undergoes preprocessing:
- Text cleaning: Removal of artifacts, unwanted symbols, and headers/footers that don’t add value.
- Structuring (optional): If the content has recognizable patterns (like paragraphs starting with “Clause” or “Section”), these can be tagged and categorized during preprocessing.
- Step 3: Storing and Indexing Unstructured Data
- The unstructured text content is indexed in Azure Cognitive Search. Unlike structured data, unstructured text is indexed for full-text search.
- This allows users to search for any keyword or phrase within the body of the contract, regardless of where it appears.
Summary of the Approach
| Step | Structured Content | Unstructured Content |
|---|---|---|
| Extraction | Azure Form Recognizer extracts labelled fields and tables from the contract image. | Azure Cognitive Services OCR converts text in images into machine-readable text. |
| Preprocessing | Data is normalized into key-value pairs. | Text is cleaned and optionally tagged for better indexing. |
| Indexing | Structured fields (e.g., “Contract Date,” “Client Name”) are indexed in Azure Cognitive Search. | The entire text is indexed for full-text search in Azure Cognitive Search. |
| AI Enrichment | Cognitive Skills may enhance the data (e.g., extracting key phrases). | Text Analytics and Cognitive Skills extract key terms and entities from the unstructured content. |
| Search and Query | Users can search using specific fields (e.g., “Find contracts by date or client”). | Users can perform full-text searches or natural language queries (e.g., “Find termination clauses”). |
Summary
This architecture leverages Azure Cognitive Services, Cognitive Search, and AI capabilities to build a scalable solution for indexing and searching through contracts in PDF format. With the ability to handle both structured and unstructured content, this solution should enable businesses to quickly retrieve contract details and answer complex queries using natural language processing.
Leave a comment